技术背景
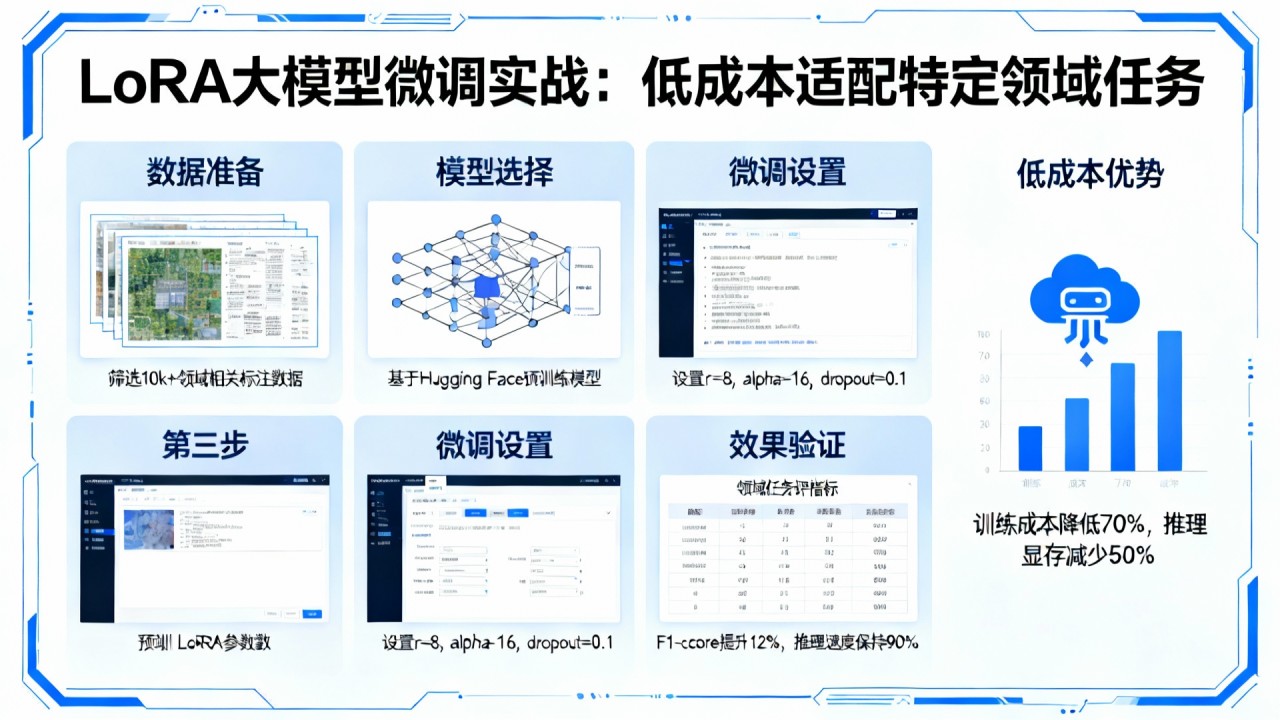
大语言模型全参数微调需要巨大的计算资源和存储空间。LoRA通过低秩分解技术,仅训练适配器参数,在保持性能的同时大幅降低资源需求,使中小企业也能定制大模型。
实现方案
基于PEFT库实现LoRA微调,支持LLaMA、ChatGLM、Bloom等多种基座模型。采用秩分解矩阵作为适配器,训练时只更新适配器参数,推理时合并权重。
代码示例
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import get_peft_model, LoraConfig, TaskType
import torch
# 模型和分词器加载
model_name = "bigscience/bloom-1b7"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# LoRA配置
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1,
target_modules=["query_key_value"]
)
# 应用LoRA
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# 训练循环
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="./lora_results",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=3e-4,
num_train_epochs=3,
fp16=True,
save_steps=500,
logging_steps=100
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
data_collator=data_collator
)
trainer.train()
# 保存适配器
model.save_pretrained("./lora_adapter")
# 推理时加载
from peft import PeftModel
model = AutoModelForCausalLM.from_pretrained(model_name)
model = PeftModel.from_pretrained(model, "./lora_adapter")配置说明
- 环境要求:Python 3.8+, PyTorch 2.0+, PEFT 0.5+, Transformers 4.28+
- 硬件要求:GPU显存≥16GB(7B模型),相比全量微调减少60%显存
- 关键参数:秩r=8,alpha=32,dropout=0.1
效果验证
在Alpaca指令数据集上,LoRA微调达到全量微调95%的性能,训练参数量仅为原模型的0.1%。使用BLEU和ROUGE指标评估生成质量。
技术优缺点
优点:大幅降低资源需求、支持多任务适配、部署灵活;缺点:性能略有损失、需要调优超参数。适用于资源有限的定制化场景。
性能优化建议
1. 选择合适的秩和alpha参数
2. 针对不同模型结构调整target_modules
3. 使用梯度检查点进一步减少显存
4. 结合量化技术实现极致压缩