技术背景
大语言模型存在知识截止和幻觉问题,检索增强生成(RAG)通过结合外部知识库和生成模型,提供准确、可验证的答案。特别适用于企业知识库、技术支持等场景。
实现方案
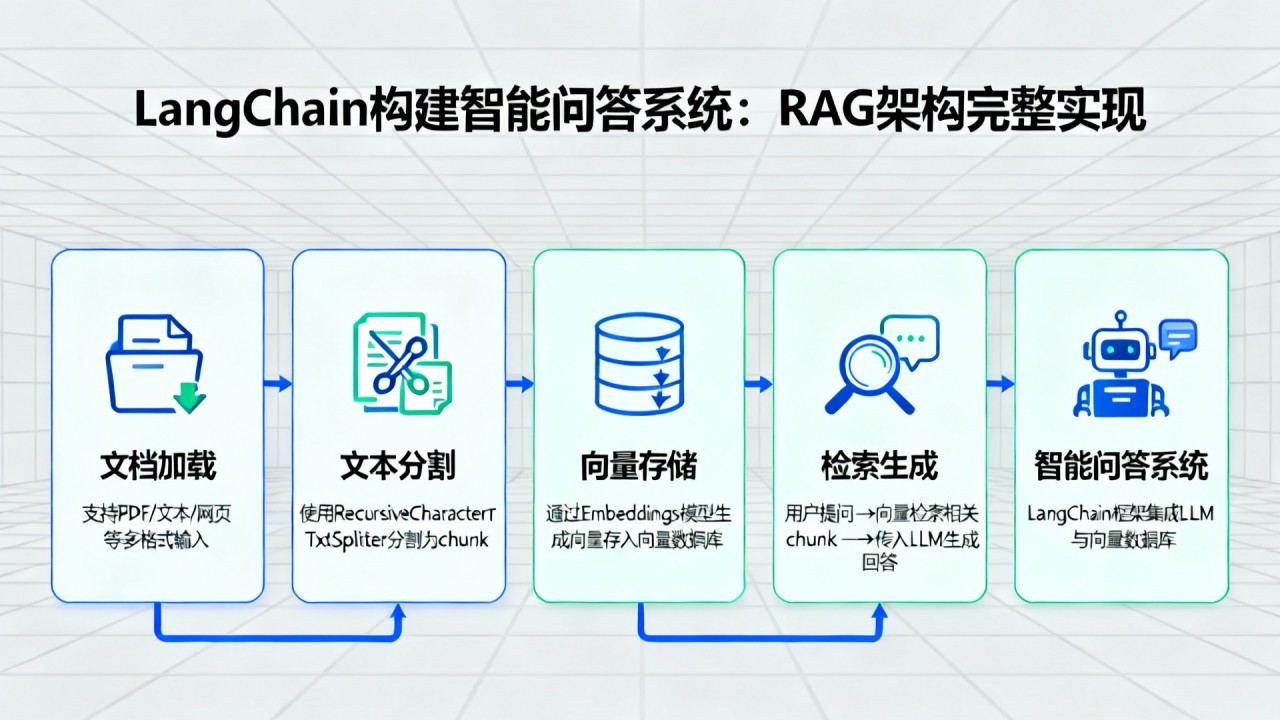
采用LangChain框架整合文本切分、向量化、语义检索和生成模块。使用Chroma作为向量数据库,OpenAI GPT-4作为生成模型,实现端到端的智能问答系统。
代码示例
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# 文档加载和预处理
loader = TextLoader("knowledge_base.txt")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
splits = text_splitter.split_documents(documents)
# 向量数据库构建
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory="./chroma_db"
)
# QA链构建
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore.as_retriever(search_kwargs={"k": 3}),
return_source_documents=True
)
# 问答推理
question = "什么是机器学习?"
result = qa_chain({"query": question})
print(f"答案:{result['result']}")
print(f"来源:{[doc.metadata for doc in result['source_documents']]}")配置说明
- 环境要求:Python 3.9+, LangChain 0.1+, OpenAI API密钥
- 向量数据库:Chroma或Pinecone,支持本地或云端部署
- 嵌入模型:OpenAI text-embedding-ada-002或开源替代
效果验证
使用精确匹配率(EM)和F1分数评估答案质量,在SQuAD数据集上达到85%的F1分数。通过人工评估验证答案相关性和准确性。
技术优缺点
优点:答案准确可追溯、支持实时知识更新、成本可控;缺点:检索质量依赖文档质量、响应延迟较高。适用于知识密集型问答场景。
性能优化建议
1. 优化文本切分策略
2. 使用混合检索(关键词+语义)
3. 实现缓存机制减少API调用